- Today
프로젝트
- Today I Learned
프로젝트
회사의 문제점과 개선점을 찾았을 때
신규 고객 유치에 미온적인 태도를 취하고 있음을 유추할 수 있었다.
이에 따라 신규 고객 유치의 중요성과 현황을 알기 위해
신규 고객들의 현황과 이들의 구매 경향, 매출에 미치는 영향을 확인하였다.
이 후, 신규 회원 유치 방안에 대하여 분석을 해보고자 하였으나,
마케팅 데이터 및 고객 세부 데이터가 부재하였고
현재 제공 받은 데이터를 토대로
최근 1년내 주문을 했던 신규 고객들은 어떤 구매경향을 가지고 있는지
고객 분류를 해보기 위해 클러스터 분석을 해보았다.
고객분류를 하기 위해 고객1명에 대한 신규 테이블을 생성
생성한 컬럼은 다음과 같다.
1. customer_id
2. first_order
3. last_orderh
4. created_month
5. total_order_cnt
6. total_price
7. purchase_cycle
8. total_category_cnt
9. order_product_cnt
10. avg_order_unit_price
11. return_cnt
12. return_category_cnt
13. avg_order_quantity
14. create_to_first_order
테이블 생성 이후 파생변수 추가: first_month, last_month
컬럼별 데이터 분포 현황을 확인하여, 일부 컬럼에서 나타났던 데이터 편향(왜도) 문제를 보완하기 위해
log scale 변환을 진행하였다.
변환한 컬럼은
1. total_order_count
2. total_price
3. category_count
4. product_count
5. avg_unit_price
6. return_count
7. avg_purchase_cycle
8. return_category_count
9. creat_to_first_order


클러스터링 할 컬럼들은 연속형 변수로만 지정
1. first_order_month
2. last_order_month
3. creat_month
4. total_order_count
5. total_price
6. category_count
7. product_count
8. avg_unit_price
9. return_count
10. avg_quantity
11. avg_purchase_cycle
12. return_category_count
13. creat_to_first_order
이 후,데이터 표준화를 하고 PCA 갯수는 2개로 클러스터링 분석을 진행
코드는 아래 접은글로!!
#라이브러리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime as dt
from datetime import timedelta
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
# ML 알고리즘
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from yellowbrick.cluster import KElbowVisualizer
# 경고 무시
import warnings
warnings.filterwarnings('ignore')
#2023년 신규 가입자
main_order['order_date'] = pd.to_datetime(main_order['order_date'])
main_order['created_at'] = pd.to_datetime(main_order['created_at'])
main_order['created_year'] = main_order['created_at'].dt.year
new_2023 = main_order.query('created_year == 2023')
#고객별 테이블 생성
customer_clustering = new_2023.copy()
customer_clustering['return_status'] = customer_clustering['return_status'].fillna(0)
customer_clustering['return_status'] = np.where(customer_clustering['return_status'] == 0,0,1)
customer_clustering['order_date'] = customer_clustering['order_date']
customer_clustering = customer_clustering.groupby('customer_id').agg(first_order=('order_date','min'),\
last_order=('order_date','max'),\
created_at=('created_at','min'),\
total_order_count=('order_id','count'),\
total_price=('total_price','sum'),\
category_count=('category','nunique'),\
product_count=('product_name','nunique'),\
avg_unit_price=('unit_price','mean'),\
return_count = ('return_status','sum'),\
avg_quantity = ('quantity','mean')).reset_index()
#구매 주기 파악
order_frequency = new_2023[['customer_id','order_date']].sort_values(['customer_id','order_date'],ascending=[True,True])
order_frequency['before_order'] = order_frequency.sort_values('order_date',ascending=True).groupby('customer_id')['order_date'].shift(1)
order_frequency['frequency'] = (order_frequency['order_date'] - order_frequency['before_order']).dt.days
order_frequency = order_frequency.groupby('customer_id')['frequency'].mean().round(0).reset_index().rename(columns={'frequency':'avg_purchase_cycle'})
#테이블 병합
customer_clustering = pd.merge(customer_clustering,order_frequency,on='customer_id',how='left')
customer_clustering = pd.merge(customer_clustering,new_2023[new_2023['return_status'].isna() == False].groupby('customer_id')['category'].nunique().reset_index().rename(columns={'category':'return_category_count'}),how='left',on='customer_id')
customer_clustering['return_category_count'] = customer_clustering['return_category_count'].fillna(0)
customer_clustering['create_to_first_order'] = (customer_clustering['first_order'] - customer_clustering['created_at']).dt.days
customer_clustering['avg_purchase_cycle'] = customer_clustering['avg_purchase_cycle'].fillna(0)
customer_clustering
#PCA(주성분 분석) n = 2
pca_main = customer_clustering.copy()
#날짜변수 처리
pca_main['first_order_month'] = pca_main['first_order'].dt.month
pca_main['last_order_month'] = pca_main['last_order'].dt.month
pca_main['create_month'] = pca_main['created_at'].dt.month
#컬럼 선택
feature_names = ['first_order_month', 'last_order_month', 'create_month',
'total_order_count', 'total_price', 'category_count',
'product_count','avg_unit_price', 'return_count',
'avg_quantity', 'avg_purchase_cycle','return_category_count',
'create_to_first_order']
pca_sample = pca_main[feature_names]
#log_scale 변환
pca_sample['total_order_count'] = np.log1p(pca_sample['total_order_count'])
pca_sample['total_price'] = np.log1p(pca_sample['total_price'])
pca_sample['category_count'] = np.log1p(pca_sample['category_count'])
pca_sample['product_count'] = np.log1p(pca_sample['product_count'])
pca_sample['avg_unit_price'] = np.log1p(pca_sample['avg_unit_price'])
pca_sample['return_count'] = np.log1p(pca_sample['return_count'])
pca_sample['avg_purchase_cycle'] = np.log1p(pca_sample['avg_purchase_cycle'])
pca_sample['return_category_count'] = np.log1p(pca_sample['return_category_count'])
pca_sample['create_to_first_order'] = np.log1p(pca_sample['create_to_first_order'])
#정규화
scaler = StandardScaler()
pca_sample_scaled = scaler.fit_transform(pca_sample)
#PCA 실행
pca = PCA(n_components=2)
printcipalComponents = pca.fit_transform(pca_sample_scaled)
principal_df = pd.DataFrame(data=printcipalComponents, columns = ['principal component1', 'principal component2'])
principal_df.head(5)
#설명력 체크
print(pca.explained_variance_ratio_)
print(sum(pca.explained_variance_ratio_))
#Elbow Method
model = KMeans()
# k 값의 범위를 조정해 줄 수 있습니다.
visualizer = KElbowVisualizer(model, k=(3,10))
# 데이터 적용
visualizer.fit(principal_df)
visualizer.show()
#클러스터링
optimal_k = 5
kmeans = KMeans(n_clusters=optimal_k, random_state=42, init = 'k-means++')
clusters = kmeans.fit_predict(principal_df)
principal_df['cluster'] = kmeans.labels_
#군집별 라인그래프
pca_sample_cluster = pd.DataFrame(pca_sample_scaled)
pca_sample_cluster.columns = feature_names
pca_sample_cluster
pca_sample_cluster['cluster'] = kmeans.labels_
pca_sample_cluster.groupby('cluster').mean().T.plot(figsize=(15,10))
# kmeans 시각화
plt.figure(figsize=(15, 10))
sns.scatterplot(data=principal_df, x='principal component1', y='principal component2', hue='cluster', palette='viridis')
plt.title('KMeans Clustering Results')
plt.xlabel('PCA 1')
plt.ylabel('PCA 2')
plt.show()
#해당 군집화 실루엣 계수
score_samples = silhouette_score(principal_df, kmeans.labels_)
principal_df['silhouette_coeff'] = score_samples
print(np.mean(score_samples))클러스터링 결과
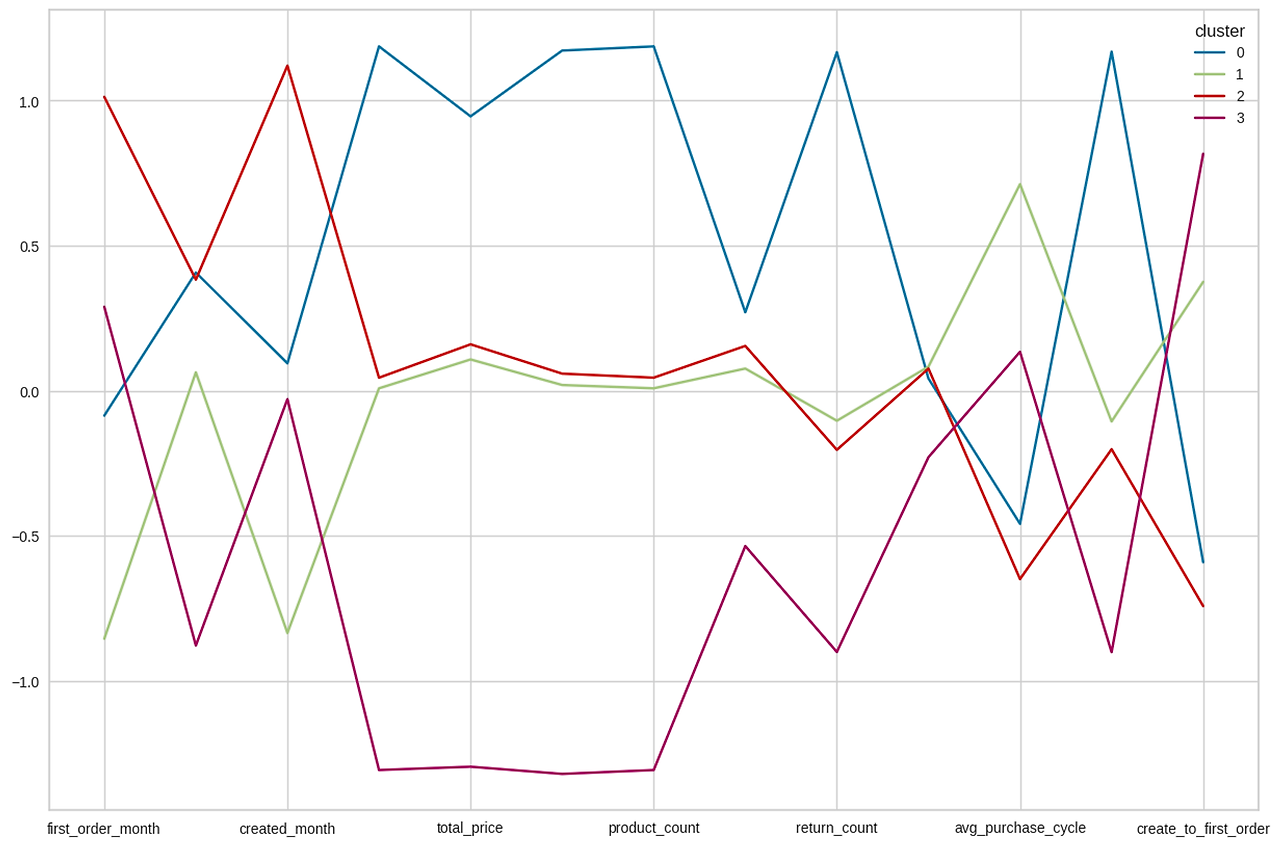

PCA 설명력: 0.6 , 실루엣 계수: 0.43
0번 클러스터
: 첫 주문한 달이 상반기, 마지막 주문한 달이 하반기이며 총 구매 건수, 총 매출액이 높으며 구매한 상품종류가 많다.
또한, 반품 건수 및 반품을 시도한 카테고리 갯수가 높으며 평균 구매 주기와 가입 후 첫 구매까지 걸리는 기간이 짧다.
→ 일주일 이내의 짧은 주기로, 평균 이상의 구매 횟수 (약 27회) 및 약 27종류의 제품 구매,
첫 구매까지 일주일가량(단기간 구매), 평균 13,000 달러의 매출 발생
매출액 기준 카테고리: 1,2,3, 위가 컴퓨터 관련
1번 클러스터
: 첫 주문한 달이 가장 연초에 가까우며, 가입한 달 또한 하반기이다. 반품 횟수는 평균보다 낮은 편이며 평균 구매주기가 가장 길고, 가입 후 구매까지 걸리는 기간이 비교적 높은 편이다
→ 1달 가량의 주기로 구매, 구매 횟수 약 10회 및 약 10종류의 제품 구매, 첫 구매까지 4주 가량 소모되며
평균 4400 달러의 매출이 발생한다.
매출액 기준 카테고리: 5위 안에 컴퓨터
2번 클러스터
: 첫 주문한 달이 가장 연말에 가까우며, 가입한 달 또한 하반기이다. 반품 횟수는 평균보다 낮은 편이며 평균 구매주기와 첫 구매까지 걸리는 기간이 가장 짧았다.
→ 일주일 이내의 짧은 주기로 구매, 평균 구매 횟수 약 10회 및 10종류의 제품 구매, 첫 구매까지 5일 정도 소모(가장 짧음)
평균 4,500 달러의 매출 발생
매출액 기준 카테고리: 5위 안에 컴퓨터
3번 클러스터
: 첫 주문한 달이 하반기 이며, 마지막 주문한 달이 가장 연초에 가깝다. 총 구매 건수, 총 매출액이 가장 낮으며, 구매한 상품 종류가 가장 적다. 평균 상품 구매 단위가 가장 낮으며, 반품건수와 반품을 시도한 카테고리 갯수가 낮다. 첫 구매까지 걸리는 기간이 가장 길다.
→ 1달 가량의 주기로 구매, 구매 횟수와 제품 종류가 적다(2회,2종류), 평균 800달러의 매출 발생
첫 구매까지 걸리는 기간이 약 2달로 가장 길다.
매출액 기준 카테고리: 1. 진공청소기 2. TV 3. 여성 시계 ~~ 8. 컴퓨터
⇒ 2023년 신규 구매자들의 구매경향은 위와 같이 총 4가지의 분류로 나뉘었다.
이 중 가장 많은 매출을 발생한 고객군집은 0번으로 ,
이들은 다양한 제품들을 구매하고, 짧은 기간 내에 재구매 횟수가 높은 구매 성향을 지녔다.
또한 그 중 컴퓨터 관련 제품군이 가장 매출이 높았으며, 다양한 제품들을 구매하였기 때문에 큰 차이는 없었으나 그 중 가장 많이 찾았던 제품은 ~~이다..
이런 구매 성향을 지닌 고객군들의 매출을 더욱 높이기 위해
다양한 제품군을 유치하고 구매 횟수에 따른 로열티(리워드 프로그램) 등을 제공하는 등의 마케팅 전략과
매출이 가장 높았던 컴퓨터 관련 제품군에 대한 가격 최적화를 진행 해보는 방안을 제안한다.
또한 해당 고객군들은 반품 서비스 이용률 이 높기 때문에
반품절차 간소화에 관한 마케팅을 시도해 보는 것도 방법이 될 수 있다.
- Next
결과 정리 및 ppt 시작
'TIL' 카테고리의 다른 글
| 2024-08-06 (0) | 2024.08.06 |
|---|---|
| 2024-08-05 (0) | 2024.08.06 |
| 2024-08-01 (0) | 2024.08.01 |
| 2024-07-31 (0) | 2024.07.31 |
| 2024-07-30 (0) | 2024.07.30 |