기초 통계량 확인하기
iris.describe()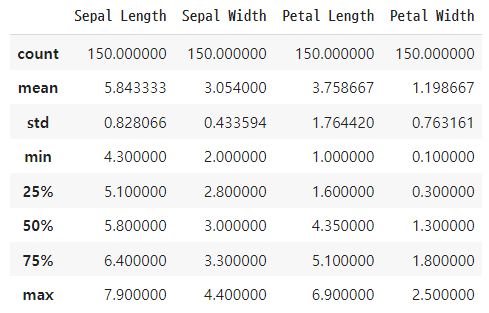
결측값 대체
iris_with_nan.info() # 결측값 포함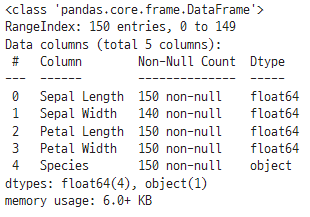
iris_with_nan2=iris_with_nan.fillna(value=0)
# fillna 사용
iris_with_nan3 = iris_with_nan.replace(np.nan,0)
# replace 사용
iris_with_nan2.info() # 결측값 제거
특정 값을 반환하여 새로운 컬럼 추가
iris["Sepal Size"] = np.where(iris["Sepal Length"].values >= 5.0 , "Large", "Small")
# np.where()
# 만족하면 "Large", 그렇지 않으면 "Small"
iris["Sepal Size"] = ["Large" if i >= 5.0 else "Small" for i in iris["Sepal Length"]]
# List Comprehension
# 삼항연산자
iris.loc[iris["Sepal Length"]>= 5.0,"Sepal Size"] = "Large"
iris.loc[iris["Sepal Length"]< 5.0, "Sepal Size"] = "Small"
# loc 로 슬라이싱
# 행 과 열을 불러온다
# 컬럼이 없다면 새로 생성됨
# 인덱스가 없을때는 불러오지 못함
참고:
https://data-newbie.tistory.com/559
https://studyweb.tistory.com/entry/Numpy-%EC%82%AC%EC%9A%A9%EB%B2%95-5-npwhere
다양한 통계량 구하기
iris.groupby("Species")[["Sepal Length","Sepal Width"]].agg([np.sum, np.mean, np.std])
# df.groupby("컬럼").agg([])
| np.std | 표준편차 |
| np.var | 분산 |
참고:
https://numpy.org/doc/stable/reference/generated/numpy.std.html
seaborn 으로 시각화
sns.scatterplot(data=iris, x="Sepal Length", y="Sepal Width", hue="Species")
# 산점도
sns.histplot(data=iris, x="Sepal Length", hue = "Species")
# 히스토그램
sns.boxplot(data=iris, x="Petal Length", hue = "Species")
# 박스플롯
참고:
https://seaborn.pydata.org/generated/seaborn.boxplot.html
'개인공부' 카테고리의 다른 글
| [데벨챌] 그로스 해킹 독서 리뷰 2주차 (3) | 2024.11.18 |
|---|---|
| [데벨챌] 그로스 해킹 독서 리뷰 1주차 (2) | 2024.11.10 |
| [Python] 시각화 그래프 (0) | 2024.05.10 |
| [Python] Pandas 함수 정리 (0) | 2024.05.09 |
| 파이썬 개인 과제 (0) | 2024.05.02 |