- 프로젝트명: 은행 고객데이터를 이용한 서비스 분석
- 기간: 2024-05-17~24
- 활용 데이터: https://www.kaggle.com/datasets/khanmdsaifullahanjar/bank-user-dataset
Bank User Dataset
This dataset contains user behaviors contributing to their credit score
www.kaggle.com
다량의 데이터가 있고, EDA 를 진행한 결과가 많이 나올 것으로 예상되는 은행 고객데이터를 선정하여 분석해보았다.
이번 프로젝트는 이상치 및 결측치를 제거하는 것과 다양한 시각화를 사용하여 보다 효과적으로 해당 데이터를 이해하기 편하도록 준비했다.
1. 개요
- 프로젝트 진행목표: 은행 대출 팀을 위한 고개 현황 보고서 작성
- 프로젝트 주제: 고객 금융 데이터 탐색과 대출 서비스 현황 파악
2. 데이터 수집 및 소개
- 데이터 수집: kaggle
- 데이터 소개:
- 은행의 개인정보, 카드정보, 계좌정보, 투자정보, 대출정보 등이 포함된 고객 데이터
- 27개의 Columns 와 50,000개의 rows 로 구성
3. 데이터 전처리
- 이상치 & 결측치 확인

# 4분기의 지표로 Customer_ID 별 연속되는 4개의 유사한 Data 가 존재하는 것을 확인
bank.groupby('Customer_ID')['Month'].nunique()
> Name: Month, Length: 12500, dtype: int64
< 각 컬럼 상황에 맞추어 이상치 및 결측치를 대체 >
① 데이터의 연속성을 가지고 있고, 수치화가 되어 있지 않은 컬럼
'Age', 'Occupation', 'Num_Bank_Accounts', 'Num_Credit_card', 'Interest_Rate', 'Num_of_Loan', 'Credit_Mix', 'Payment_of_Min_Amount', 'Total_EMI_per_month','Num_Credit_Inquiries'
# Age 컬럼 전처리( 언더바 제거 )
result=[]
for i in bank['Age']:
if "_" in i:
i = i.replace("_","")
result.append(float(i))
bank['Age'] = result
## Age 컬럼 90 초과 및 -500 인 값 NaN으로 수정
result = []
for i in bank['Age']:
if (i > 90) :
result.append(np.nan)
elif (i < 1) :
result.append(np.nan)
else:
result.append(i)
bank['Age']=result
# NaN 값을 Customer_ID별로 NaN을 제외한 최빈값으로 대체
bank['Age'] = bank.groupby('Customer_ID')['Age'].transform(lambda x: x.fillna(x.mode()[0] if not x.mode().empty else np.nan))
# underbar(_) 제거 후 Customer_ID 의 최빈값으로 대체
# 나이 컬럼의 경우 시간이 지남에 따라 1세가 더 증가되는 경우도 있었으나 이후 연령별 segmentation 을 진행할 예정이었기 때문에 최빈값으로 대체 하였다
② 수치화가 되어 있지 않은 컬럼
'Outstanding_Debt', 'Annual_Income'
# Annual_Income 컬럼 전처리( 언더바 제거 )
result= []
for i in bank['Annual_Income']:
if "_" in i:
i = i.replace("_","")
result.append(float(i))
bank['Annual_Income'] = result# underbar(_) 제거
③ 음수 및 이상치가 포함된 컬럼
'Delay_from_due_date', 'Changed_Credit_Limit', 'Num_of_Delayed_Payment'
#Changed_Credit_Limit 컬럼 언더바를 0으로 변경
bank['Changed_Credit_Limit'] = np.where(bank['Changed_Credit_Limit']=='_',0,bank['Changed_Credit_Limit'])# 0으로 대체
④ 결측치가 있었던 컬럼
'Monthly_Inhand_Salary'
# Monthly_Inhand_Salary 에 nan값을 평균값으로 변환
def fill_mean(df, group_col, target_col):
mean_val = df.groupby(group_col)[target_col].transform('mean')
nan_ = df[target_col].isna()
df[target_col].fillna(mean_val, inplace=True)
filled_count = nan_.sum()
return filled_count
fill_mean(bank,'Customer_ID','Monthly_Inhand_Salary')
# nan값인 'Monthly_Inhand_Salary'를 0으로 변경
bank['Monthly_Inhand_Salary'] = bank['Monthly_Inhand_Salary'].replace(np.NaN,0)# Customer_ID 의 평균값으로 대체
# 월급 특성상 급여의 변화가 크지 않을 것이라고 예상하여 평균값으로 대체 하였다
# 평균값이 존재하지 않은 데이터는 0 으로 대체
⑤ 매달 1개월씩 증가하는 연속성을 가진 컬럼
'Credit_History_Age'
#“Credit_History_Age”
bank_CHA=bank[['Credit_History_Age']]
CHA_list = bank_CHA.values.tolist()
Hist_M = []
for i in sum(CHA_list, []) :
if pd.isna(i) :
Hist_M.append(0)
else :
str_CHA = i.strip().split(' ')
re_list_CHA = [str_CHA[0], str_CHA[3]]
L_CHA = list(map(int, re_list_CHA))
M_sum = L_CHA[0]*12+L_CHA[1]
Hist_M.append(M_sum)
Re_List = []
for idx, val in enumerate(Hist_M) :
if val == 0 :
if idx%4 == 0 :
Re_List.append(Hist_M[idx+1]-1)
else :
Re_List.append(Hist_M[idx-1]+1)
else :
Re_List.append(val)
Hist_Age = []
for i in Re_List:
years = i // 12
months = i % 12
Hist_Age.append([years, months])
List_to_DF = []
for idx,val in enumerate(Hist_Age) :
ststring = str(val[0])+' Years and '+str(val[1])+' Months'
List_to_DF.append(ststring)
bank['Credit_History_Age'] = List_to_DF# 등차수열로 대체
# 4개월 간의 데이터가 반복적으로 나타나고 있었으며, 이 전 값에서 1달씩 더해주었다.
- 새로운 csv 파일 생성
해당 데이터 내에 결측치와 이상치가 다량 존재하였고,
위와 같이 전처리 후 데이터를 통합하여 새로운 csv 파일을 생성하고 EDA 를 진행하였다.

- EDA 를 위한 특정 컬럼 Segmentation
- 연령별 - 10
- 연간소득별 - 30k
- 대출종류별 - Unique 값

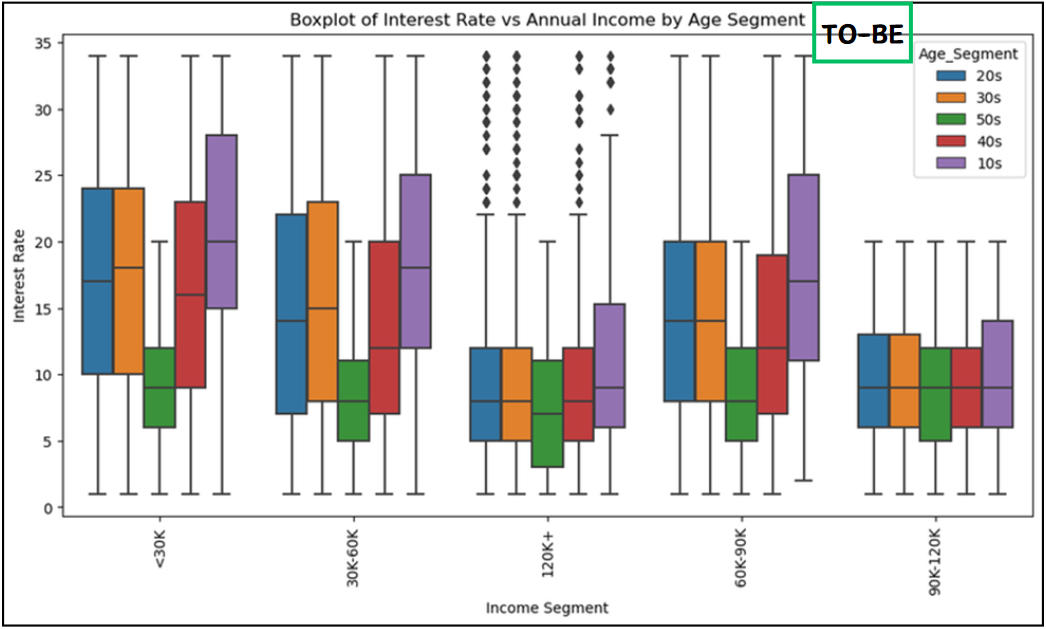
- 현황분석
① 데이터 현황
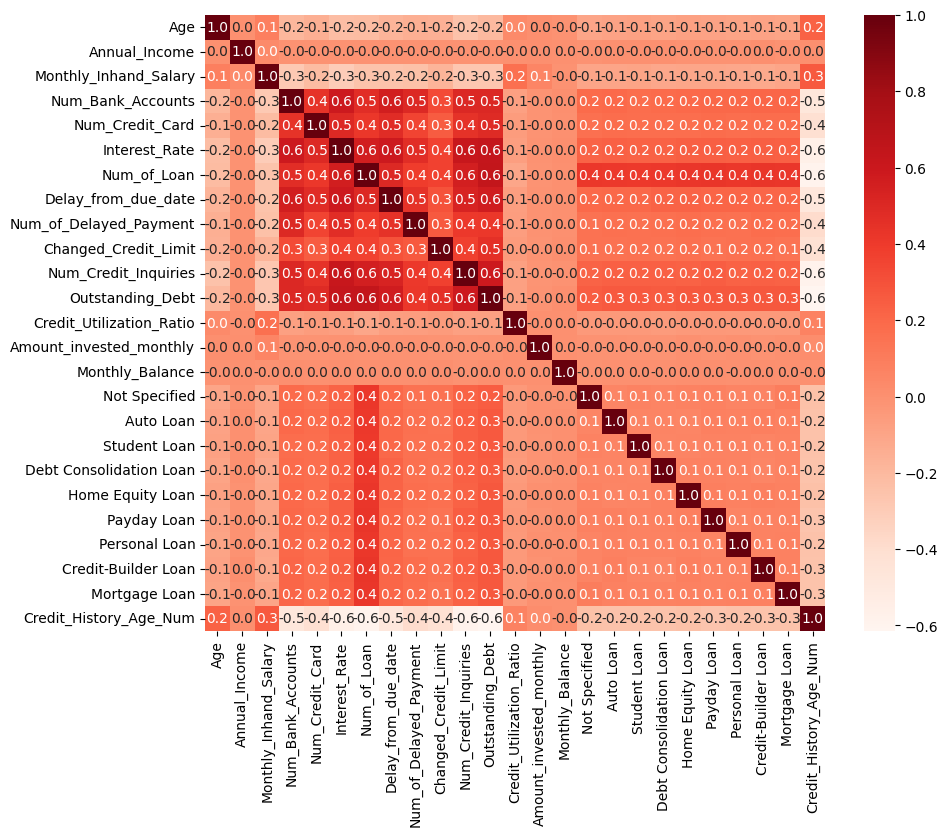
# 미지불 채무액(Outstanding_Debt)기준
- 양의 상관관계:
대출건수(Num_of_Loan), 이자율(Interest_Rate),
대출 마감 지연일(Delay_from_due_date), 신용조회건수(Num_credit_Inqueries)
> 미지불 채무액이 증가할 수록 증가
- 음의 상관관계:
계좌유지기간(Credit_History_Age)
> 미지불 채무액이 증가할 수록 감소
*양의 상관관계:
한 변수가 증가할 때 다른 변수도 같이 증가
*음의 상관관계:
한 변수가 증가할 때 다른 변수는 감소

# Numeric 컬럼 간의 상관관계:
미지불 채무(Outstanding_Debt)와 대출건수(Num_of_Loan)
두 컬럼 사이에서 0.638713 로 다른 컬럼들 중 가장 높은 양의 상관관계를 가지고 있다

- 시각화
① Age 컬럼을 사용한 시각화

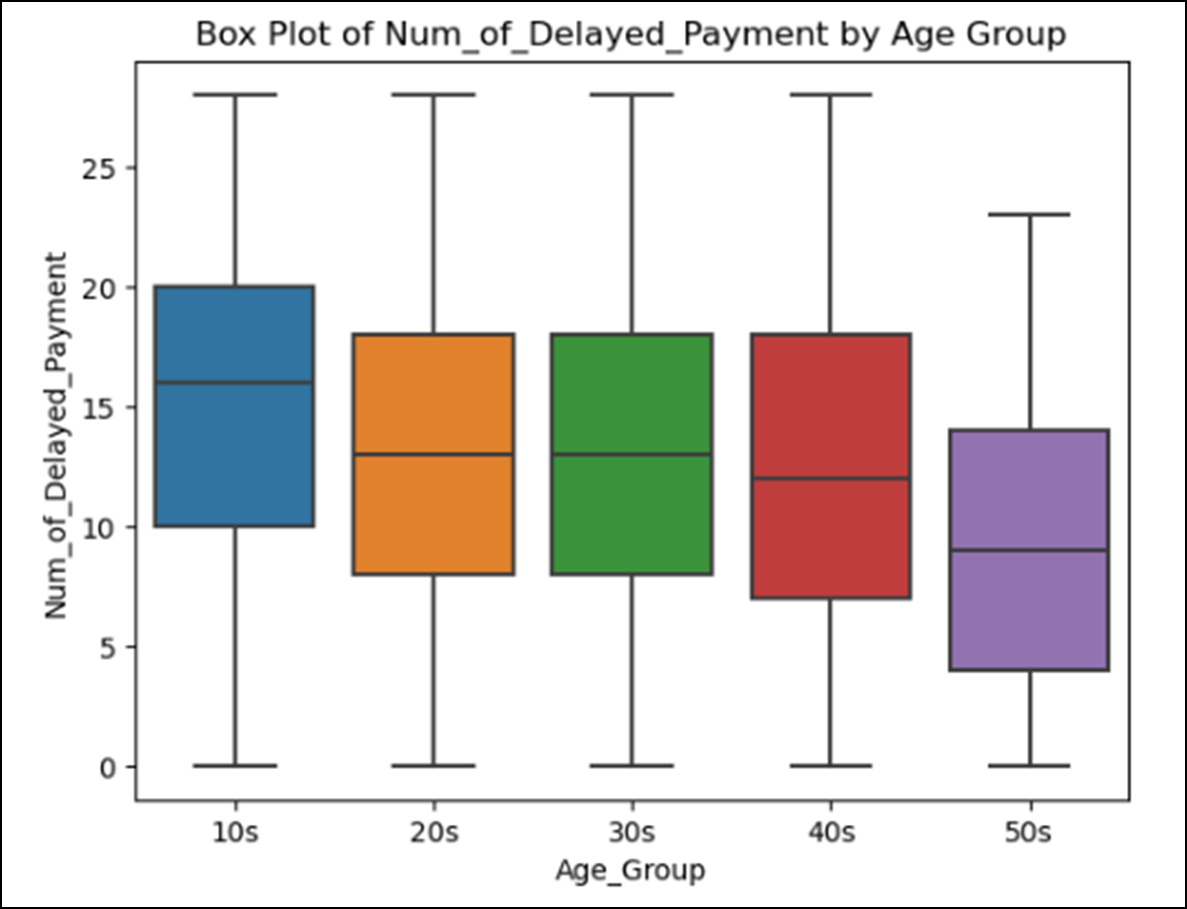
# 연령대가 높아짐에 따라 이자율과 대출 지연건수가 낮아지는 경향이 있다.
> 저연령대의 고객층을 조금 더 신경써야될 것으로 보인다.
② Credit_Mix 컬럼을 사용한 시각화

# 비례 관계를 가진 컬럼:
계좌 유지 기간(Credtit_History_Age)
> 높아질수록 신용도가 높다.
# 반비례 관계를 가진 컬럼:
보유계좌갯수(Num_Bank_Accounts), 이자율(Interest_Rate),
대출마감지연일(Delaty_from_due_date), 보유카드갯수(Num_credit_Card),
대출건수(Num_of_Loan), 대출마감지연건수(Num_of_Delayed_Payment)
> 높아질 수록 신용도가 낮다.
③ Outstanding_Debt 컬럼을 사용한 시각화
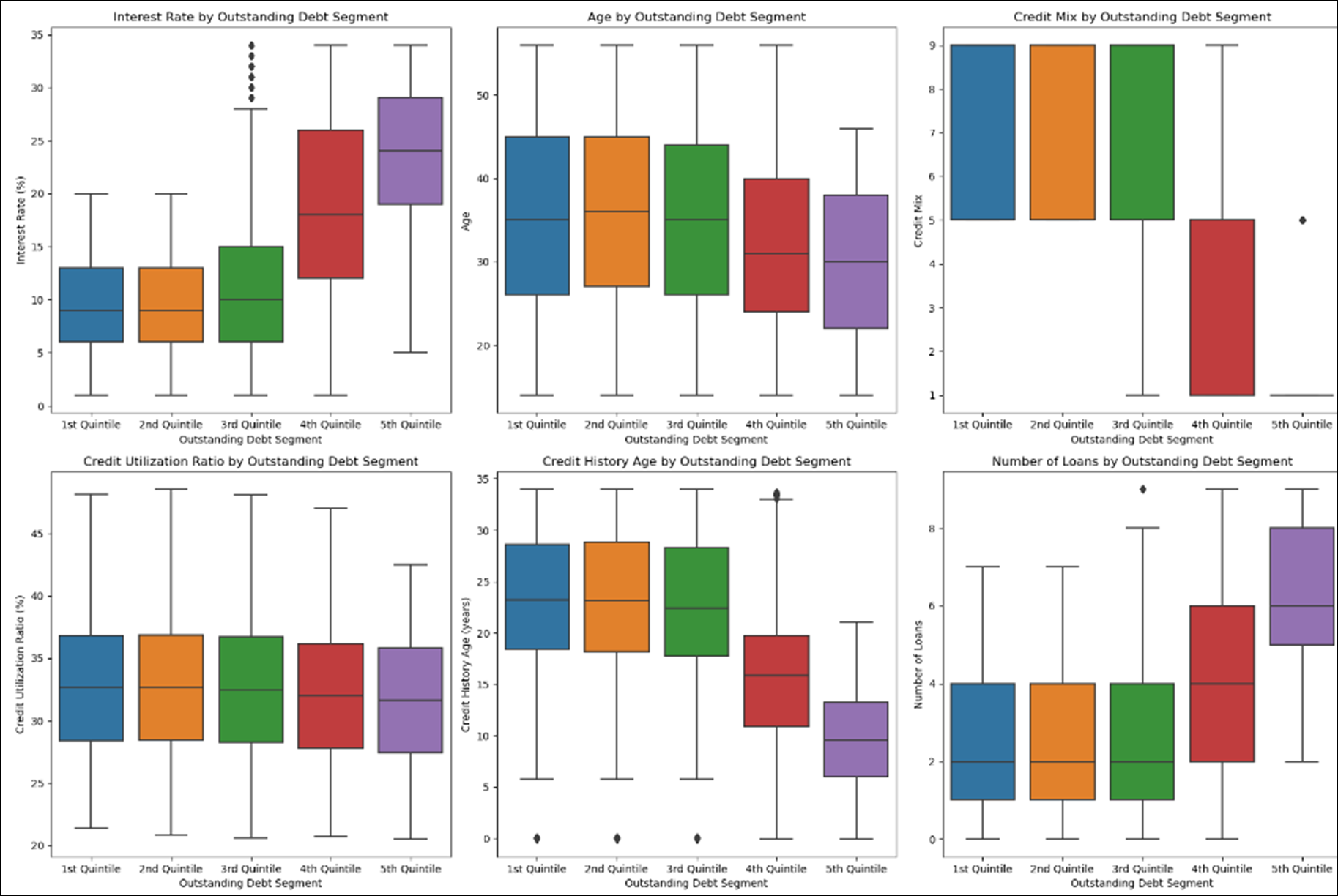
# 이자율(Interate_rate)과 대출건수(Num_of_Loan)가 높을 수록 미지불 채무 금액이 높다.
# 계좌유지기간(Credit_History_Age)이 높을 수록 미지불 채무 금액이 낮다.
* 신용도와 미지불채무액의 관계
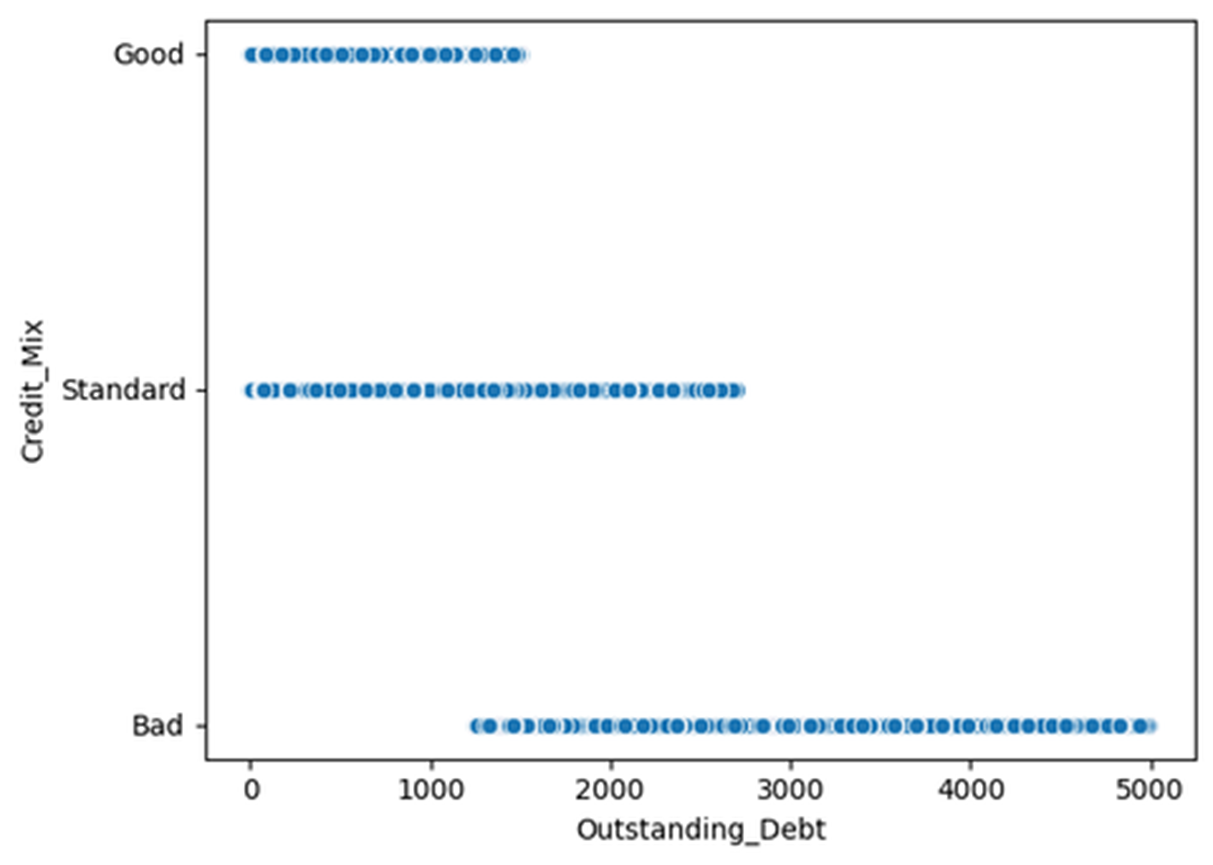
# 신용도가 낮을수록 큰 금액의 채무를 갖고 있다.
- 미국 은행 시스템 상 본인이 사용할 수 있는 한도 내에서 적절하게 사용할 경우 신용도가 상승한다.
- 사용자들이 잘 사용하고 있는 것으로 파악된다.
④ Outstanding_Debt 의 회귀분석
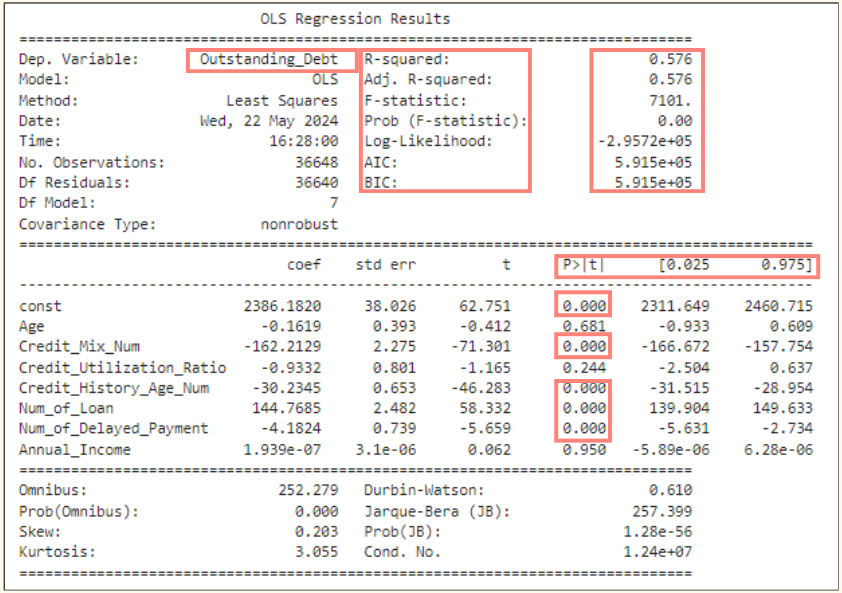
* 회귀분석이란?
원인과 결과가 서로 연속되는 개념으로 이해하는 것이다.
독립변수로 종속변수(목표변수)를 예측하는 것
# ols 모델명을 사용하였다.
# 다만, 모델의 적합도가 높지 않아 유의미하지 않은 모델일 수 있다.
# P>|t| (유의확률) : 0.05
# 오차범위 5% 내외인 컬럼들은 유의미하다.
- 컬럼:
신용도(Credit_Mix_Num), 계좌유지기간(Credit_History_Age_Num),
대출건수(Num_of_Loan), 대출 마감 지연 건수(Num_of_Delayed_Payment)
5. 결론
- 직업군별의 부채 금액차가 크지 않다
- 데이터 분포가 대부분 비슷한 것으로 보여 데이터가 올바른지에 대한 의심도 필요하다.
- 모든 종류의 대출이 골고루 판매되었다.
- 신용도에 따라 특화된 대출 상품을 구상하면 좋을 것으로 보인다.
- 신용도 산정 기준으로 채무, 대출 지연 건수 등을 잘 이용하고 있다.
- 연령대가 낮을 수록 채무와 대출 지연 건수가 많으며 신용도가 낮다.
- 저연령 고객층에 대한 리스크 관리가 필요하다.
6. 회고
- 기간
- 테이블 내에 특정 한 해의 4분기의 데이터만이 존재했기 때문에 비교 대조군으로 데이터를 나눌 수 없었는 아쉬움이 있다.
- 컬럼 정보 설명 부족
- 해당 컬럼이 의미하는 바가 명확하지 않아 EDA 진행 시 데이터를 이해하는데 어려움이 있었다.
- 다량의 이상치 & 결측치
- 이상치 및 결측치가 많아 컬럼에 맞는 대체 값을 찾아 전처리 진행에 많은 시간이 투자되었다.
- 도메인 지식 부족
- 미국의 소득 분위 기준 구간에 대한 정보 부재로 해당 데이터 내에 있는 연간소득으로만 세그먼트를 진행하였다.
- 금융 관련 지식이 부족하여 다양한 방법으로 관계를 추출하는데 어려움을 겪었다.
KPT 회고
https://lyj-01.tistory.com/159
'Project' 카테고리의 다른 글
| [Team Project] 성장기 도약의 KEY가 되는 신규 가입자 유치 전략 (3) | 2024.08.27 |
|---|---|
| [Team Project] Amazon Fresh 의 미래, 세그먼트별 수익성 개선 전략 수립 (0) | 2024.07.12 |
| [Team Project] 구매 성향에 따른 분류와 그에 따른 마케팅 방안 제시 (0) | 2024.06.25 |
| [Mini Team Project] 상품 판매 데이터 분석에 따른 판매 상품 추천 (1) | 2024.04.19 |