- Today
1. 프로젝트 ppt 작성
2. python basic 수강
- Today I Learned
Python Basic
Merge
컬럼 기준으로 병합( join 과 유사 )
pd.merge(df2,df3)
주요옵션(파라미터)
on: 공통 컬럼, [] 리스트 형태로 만들어주면 여러개도 사용 가능
how: 어떤 방식으로 조인(inner, outer,left,right)
> 현업에서는 inner, left 사용
left on / right on: 열의 공통컬럼이 이름이 다를 때 사용
# 기준열 이름이 다를 때
merge_df = pd.merge(df2,df3, how='inner', left_on = 'Customer ID', right_on = 'user id')
join
축(인덱스) 기준으로 병합
df.join(df2)
주요옵션
how
lsuffix = '1', rsuffix = '2': 컬럼이름이 같을 경우 오류, 옵션으로 설정하여 조인 가능
concat
특정 축을 따라 연결( union 과 유사 )
# 기본 작성구문
pd.concat([df2, df3])
주요옵션
axis=0 수직결합(기본값) / axis=1 수평결합
join: 어떤 조인 방식 (inner, outer, left, right)
# 세로로 결합
pd.concat([df2, df3], axis=0, ignore_index=True, join='inner')
append
수직(행) 기준으로 결합
df.append(df2)
피봇테이블
데이터의 열을 기준으로 피벗테이블을 변환
# age 라는 축을 기준으로 카테고리별 고객id 카운트
pd.pivot_table(df2, index='Age', columns='Category', values='Customer ID', aggfunc='count')
# age, Category 라는 축을 기준으로 성별 Previous Purchases 최소, 최대값 구하기
pd.pivot_table(df2, index=['Age','Category'],columns='Gender', values='Previous Purchases', aggfunc=['min','max'])
index: 축으로 사용될 열
columns: 열로 사용될 열
values: 값으로 사용될 열
aggfunc: 계산
lambda
이름이 없는 함수
함수를 한번만 사용하거나 함수를 인자로 전달해야하는 경우 사용
# lambda 함수를 이용한 정렬
mylist = ['apple', 'banana', 'cherry']
mylist2 = sorted(mylist, key=lambda x: len(x))
print(mylist2)
응용
# '.' 구분자를 기준으로 데이터를 나누고 컬럼으로 받음
# lambda 함수와 결합하여 사용하는 경우
# 7번 반복, a 를 컬럼 구분자로 받아주고, format 함수를 통해 a0, a1, a2 ... 로 표기
# lambda 함수를 통해 '.' 로 구분. 단, len(x.split('.') 즉 7 보다 i 가 작을 때 수행
# 중요
for i in range(7):
df2["a{}".format(i)] = df2['x'].apply(lambda x: x.split('.')[i] if len(x.split('.'))>i else None)
df2['x'].apply(lambda x
x 컬럼에 접근할 것이다.
rrule
dateutil 라이브러리에 속한 함수
날짜 데이터를 원하는 기준에 따라 output 으로 가져올 수 있다.
freq: 반복 주기( SECONDLY, MINUTELY, HOURLY, DAILY, WEEKLY, MONTHLY, YEARLY )
dtstart: 시작하는 날짜
until: 끝나는 날짜
date 를 원하는 형식대로 출력
strftime('%Y-%m-%d')
프로젝트
ppt 작성 및 필요 데이터 시각화
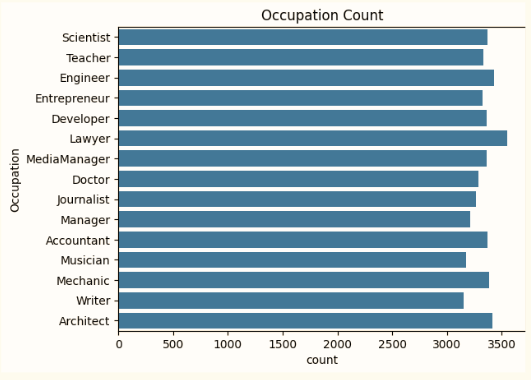
직업별 고객수
나이분포

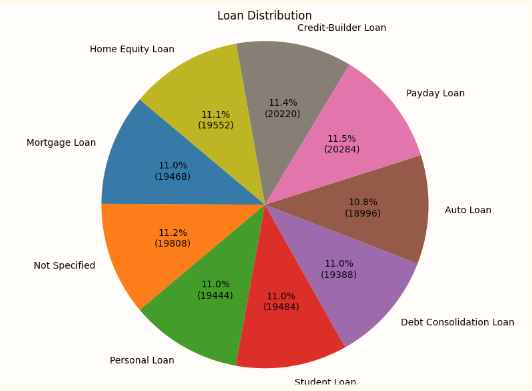
대출의 종류 비율
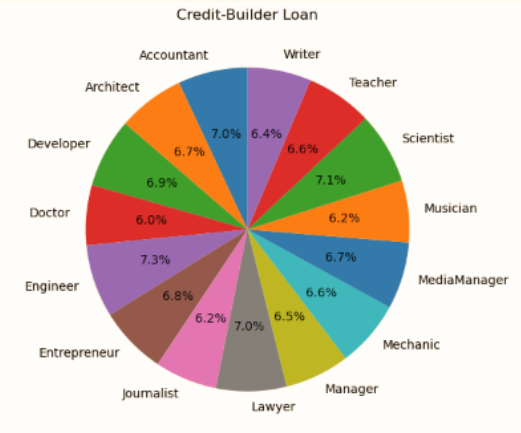
대출별 직업 비율
대출 종류별 개수 시각화

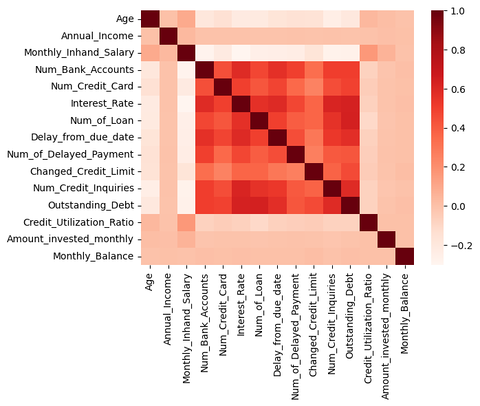
상관계수 분석을 위한 히트맵 시각화
Age_Segment 와 Interest_Rate 시각화

Age_Segment 와 Num_of_Delayed_Payment 시각화

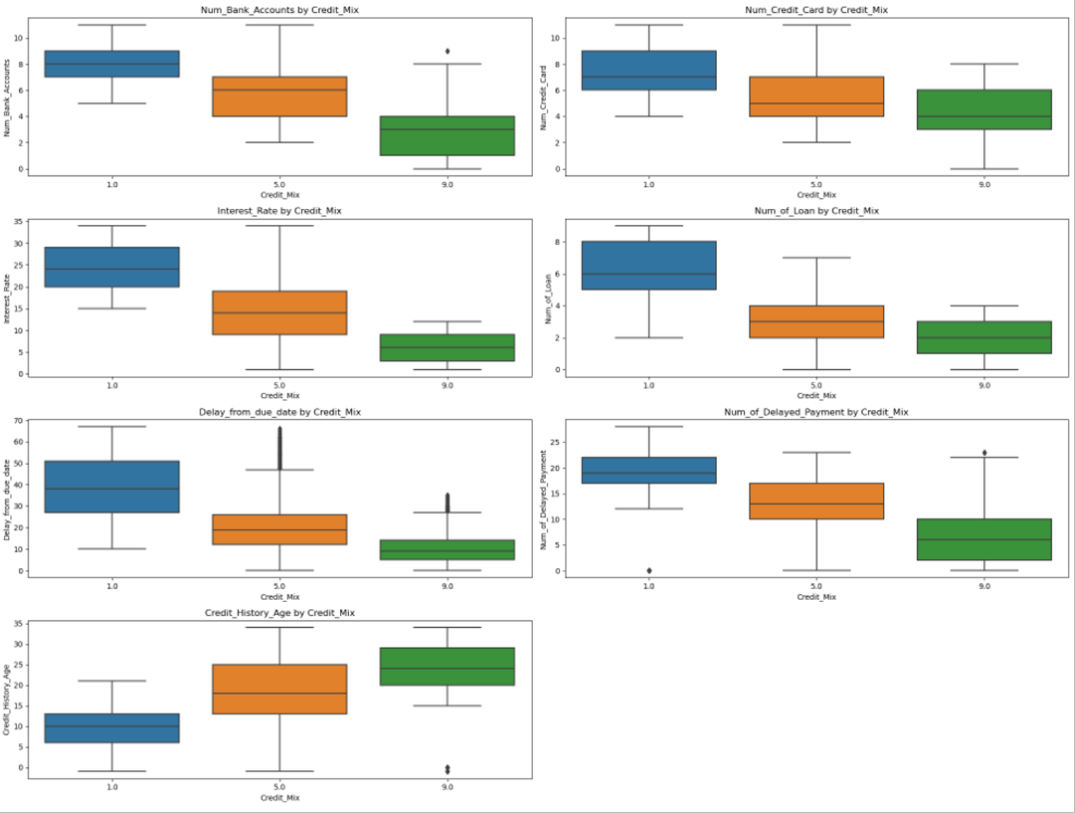
Credit_Mix 시각화
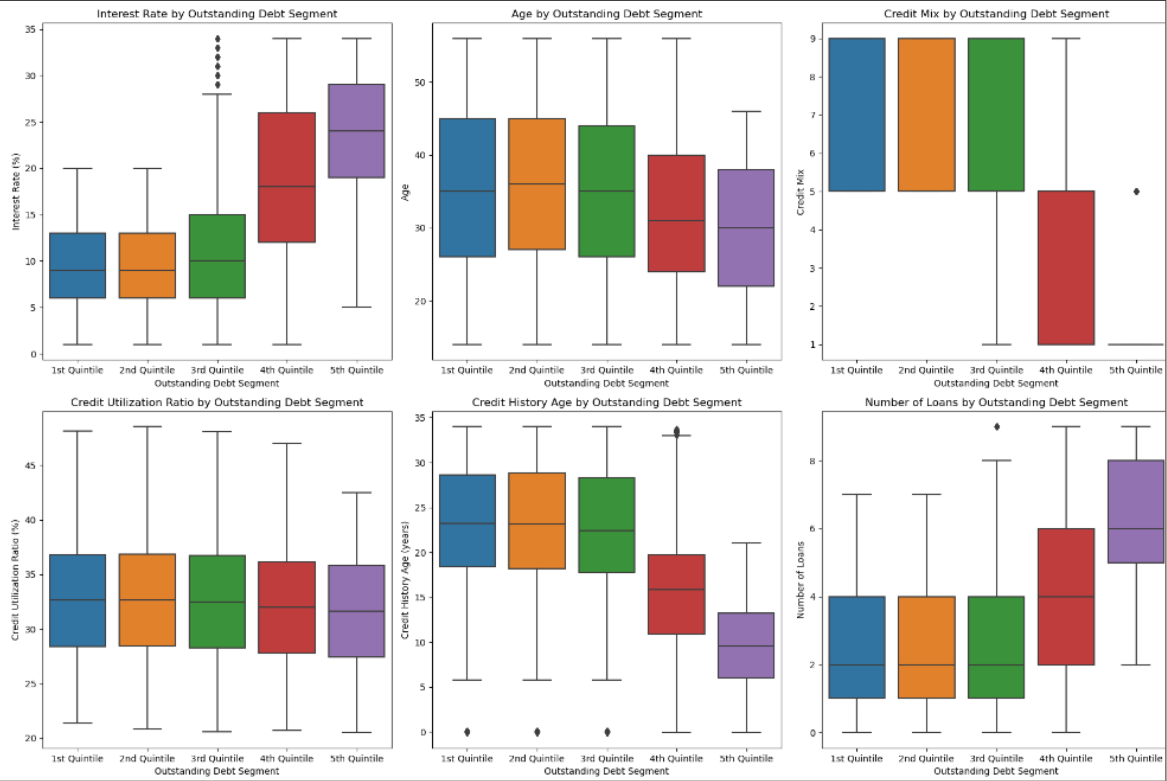
Outstanding Debt 시각화
회귀분석

회귀분석의 결과:
P>|t| (유의확률): 0.05 이하 인
Credit_Mix_Num,
Credit_History_Age_Num,
Num_of_Loan,
Num_of_Delayed_Payment,
Annual_Income
위 칼럼들은 오차범위 5% 내외로 유의미하다.
- Next
프로젝트 대본 작성
'TIL' 카테고리의 다른 글
| 2024-05-24 (0) | 2024.05.24 |
|---|---|
| 2024-05-23 (0) | 2024.05.23 |
| 2024-05-21 (0) | 2024.05.21 |
| 2024-05-20 (0) | 2024.05.20 |
| 2024-05-17 (0) | 2024.05.17 |