- Today
1. SQL 코드카타 2문제
2. 대시보드
3. 통계학 2회차 라이브 세션 수강 및 복습
4. 머신러닝 기초 완강
- Today I Learned
통계학 2회차
A/B 테스트: 기존과 변형시켰을 때 어떤게 더 효과가 있었는지 테스트 하는 것
목적: UI/UX 개선, 전환율 증가, 매출 증가
주요지표: 가입율, 재방문율, CTR(노출 대비 클릭율), CVR(클릭 대비 전환율,구매전환율),ROAS(캠페인 비용 대비 캠페인 수익), eCPM(1,000회 광고 노출당 얻은 수익)
<프로세스>
1. 현행 데이터 탐색
: 주요 지표를 기준으로 현재 데이터 탐색
2. 가설 설정
: 목표 달성을 위한 KPI 정의
*KPI: 기업마다 다름 ( 매출, 방문율 등 )
귀무가설: 처음부터 버릴 것을 예상하는 가설, 차이가 없을 것이다, 차이가 있어도 조금 있다(의미 있는 차이가 없다)
대립가설: 귀무가설에 대립, 차이가 있을 것이다, 유의미한 차이가 있을 것이다.
ex) 성별과 사이즈에 관계가 있을 것인가?
귀무가설: 성별과 사이즈는 관련성이 없을 것이다.
대립가설: 성별과 사이즈는 관련성이 있을 것이다.
3. 유의수준 설정
: 귀무가설을 얼마나 신뢰할 것인지 기준을 정하는 단계
: 귀무가설이 맞을 때 오류를 얼마나 허용할 것인지
ex) 신뢰도 95%, 유의수준 5%
4. 테스트 설계 및 실행
: 대조군과 실험군의 두 그룹으로 분리
5. 테스트 결과 분석
: 가설에 대해 통계적으로 분석하여 유의미한 차이가 있었는지 없었는지 확인
ex. 검정통계량 분석
<주의사항>
적절한 표본 크기
하나의 변수만 변경
무작위성
적절한 분석 방법
테스트 결과의 의미
정해진 기간 동안 진행
> 너무 많이 할 경우 고객의 이탈을 유발할 수 있음
유의수준: 오류 허용 범위
: 신뢰도의 반대말
: 확률값이므로 0부터 1 사이의 값을 가진다.
: 통상적으로 신뢰도 95%, 유의수준 5%
검정통계량
: 귀무가설을 채택 또는 기각하기 위해 사용하는 확률변수를 의미
*확률변수: 특정 확률로 발생하는 각각의 결과를 수치값으로 표현하는 변수
: 표본 평균, 비율, 상관 계수 간의 차이 등 다양한 형태를 취할 수 있다.
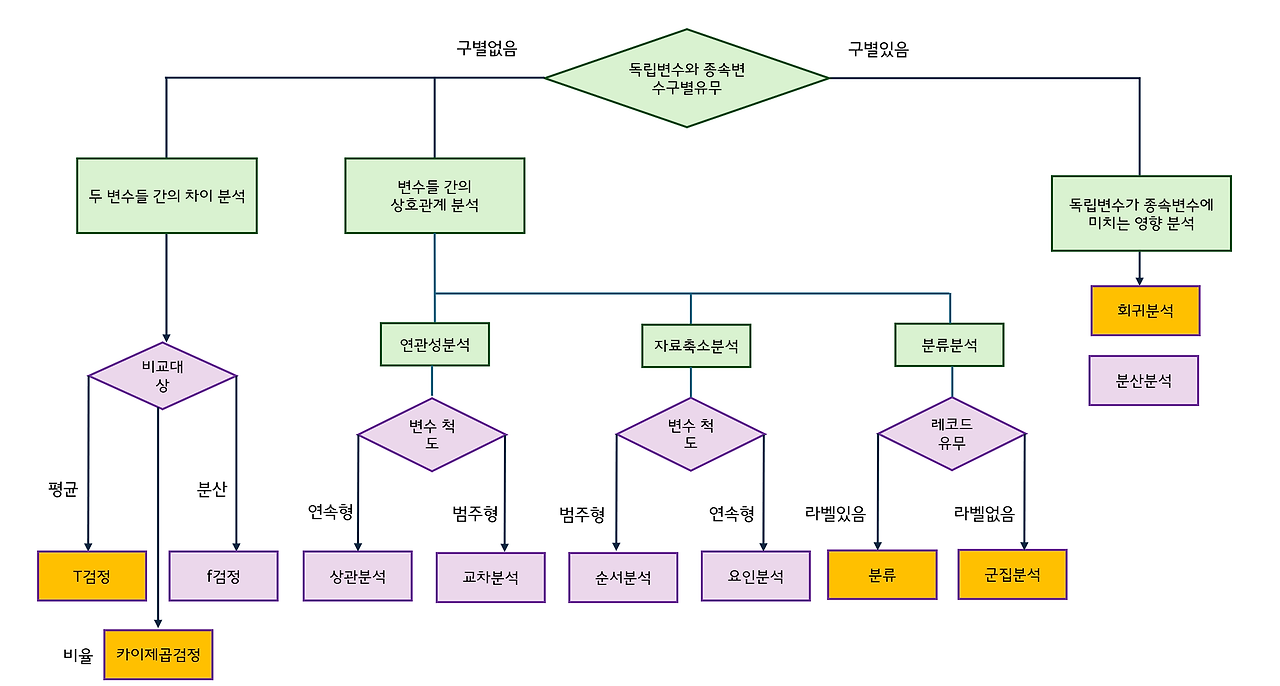
* 검정 방식의 선택은 가설과 데이터 종류에 따라 달라진다.
| 검정 방식 | 비교대상 | 대상 |
| Z 검정 | 표본의 평균(차이 분석) 모집단의 분산을 알 수 있는 경우 |
연속형 자료 |
| T 검정 | 표본의 평균(차이 분석) 모집단의 분산을 알 수 없는 경우 |
연속형 자료 |
| 카이제곱검정 | 표본의 분산(상관관계 분석) | 범주형 자료 |
| F 검정 | 표본의 분산(상관관계 분석) | 범주형 자료 |
> 검정방식을 통해 p-value(숫자) 가 나온다.
p-value: 어떤 사건이 우연히 발생활 확률
p 값이 작을 수록 (ex.유의수준인 0.05 보다 작으면 ) 우연히 일어났을 가능성이 거의 없다
> 인과관계가 있다 > 대립가설 채택
p 값이 클수록 (ex. 유의수준인 0.05 보다 크면 ) 우연히 일어났을 가능성이 크다
> 인과관계가 없다 > 대립가설 기각
>> 유의수준과 p-value 로 판단하여 나온 숫자 값으로 판단(유의한지 아니한지 확인)
가설설정 1
귀무가설: 남성과 여성의 구매금액에 차이가 없을 것이다
대립가설: 남성과 여성의 구매금액에 차이가 있을 것이다
t-test 사용
import scipy.stats as stats
t, pvalue=stats.ttest_ind(표본1,표본2)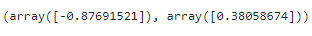
# tscore(-0.87691521): 검정통계량/양의 값으로 크면 클수록 차이가 크다. 작을수록 차이가 없다는 것
음수이든, 양수이든 차이가 크다.
# p-value(0.38058674): 우연히 일어날 확률
# 유의수준: 0.05, 신뢰도: 95%
>> p-value 값은 0.05보다 크므로, 인과관계가 없다 / 대립가설 기각
>> 남성과 여성의 구매금액에 차이가 없다.
가설설정 2
귀무가설: 성별과 구매 size 에는 관련성이 없을 것이다
대립가설: 성별과 구매 size 에는 관련성이 있을 것이다
카이제곱 검정
import scipy.stats as stats
# 라이브러리의 crosstab 함수를 사용해 범주형 자료의 빈도표 만들기
stats.chi2_contingency(observed=자료)
crosstab 함수: 빈도비교

# 카이제곱 검정통계량(6.615107840598039)

# p-value(0.08523181331915772)
>> p-value 값은 0.05보다 크므로, 인과관계가 없다 / 대립가설 기각
>> 성별과 구매 size 에는 관련성이 없을 것이다.

# 자유도(3)
* 자유도와 유의수준을 통해 귀무가설 기각 여부를 판단하기도 한다.
자유도와 유의수준 표의 숫자를 넘지 못한다면 귀무가설 채택
자유도 계산식?
(변수1 그룹의 수 -1) * (변수2 그룹의 수 -1)
* p 밸류가 절대적인 것은 아니다.
- Next
1. SQL 코드카타 1문제
2. 머신러닝 심화 수강
3. 대시보드
'TIL' 카테고리의 다른 글
| 2024-06-10 (0) | 2024.06.10 |
|---|---|
| 2024-06-07 (0) | 2024.06.07 |
| 2024-06-04 (0) | 2024.06.04 |
| 2024-06-03 (1) | 2024.06.03 |
| 2024-06-02 (0) | 2024.06.02 |