- Today
1. Python Basic 3회차 수강
2. 기초통계 수강
- Today I Learned
Python Basic
결측치 처리
1. 제거
# 결측치 제거1 - 열 제거하기
df3 = df3.drop('Unnamed: 4', axis=1)
# 결측치 제거2 -결측치가 있는 행들은 모두 제거
df3.dropna(inplace=True)drop 라는 함수가 결측치를 제거하는 것인가? 했는데
다시보니 그냥 제거하는 것이었음!
* df3 를 보았을 때 모든 행이 결측치였기 때문에 그 열을 삭제 한 것

dropna(inplace=True) 에서
inplace 가 어떤 뜻인지?
* inplace 는 원본을 변경할지에 관한 여부이다.
default 값은 False 로 True 를 사용하면 원본이 변경된다
2. 대체
# 결측치 대체1 - 최빈값
df3 = df3['Interaction type'].fillna(df3['Interaction type'].mode().iloc[0])
# 결측치 대체2 - 평균값
df['sw']=df['sw'].fillna(df['sw'].mean())
# 결측치 대체3 - 중앙값
df['sw']=df['sw'].fillna(df['sw'].median())
iloc[0]
는 0번째 있는 값을 모두 처리한다는 뜻인데
이 컬럼에서 쓰는 이유를 모르겠음..
값이 하나만 있는 것이 아닌건가 ?

이런 데이터 값이면 한개만 입력되어있어도 0인건지?
그럼 다른 값으로 변환하는 건 안되는지?
fillna 에 다른 값을 넣었을 때에는 변환이 된다.. 예를 들어 숫자 나 문자 도 가능


하지만 최빈값은 변환이 안됨!
꼭 iloc[0] 이렇게 추가를 해주어야 변환이 된다...
* 정욱튜터님 멘토링
판다스에서 시리즈도 취급을 해주고 있지만
따로 순서를 지정해주지 않는다면 막무가내로 입력이 되기 때문에 순서를 지정해주어야 한다.
최빈값 등 값이 한개가 아닐 수가 있기 때문에 판다스에서는 몇번째 값을 가져오는지 알 수 없기 때문에 지정해주어야 한다!
* 머신러닝으로 사용
K-NN
: NA 값의 가장 가까운 주변 K 개의 평균을 NA 값으로 대체
: K 개에 가장 가까운 곳에 있는 값으로 대체
: 거리 기반으로 값을 대체하는 방법
** 머신러닝을 실행하기 전에 표준화를 먼저 진행해주어야한다!
표준화란? 평균을 0으로, 표준편차를 1로 바꾸는 것이다.
0 을 중심으로 양쪽으로 데이터를 분포시키는 방법.
예를 들자면
다른 방식으로 수집된 데이터의 경우 그 데이터의 값의 의미가 다를 수 있다.
일주일동안의 접속일수가 1일~ 최대 7일 이고
결제금액은 0원부터 상한선이 없다.
이 경우 접속일수의 1과 결제금액 1은 다른 의미인데 표준화를 진행하지 않으면
데이터가 너무 클 경우 숫자의 크기가 크다 라고 받아드릴 수 있다.
즉, 데이터의 범위가 클 때 0을 중심으로 압축을 시켜 데이터를 양쪽으로 분포 시키는 것
# 표준화를 진행하기 위한 라이브러리 선언
from sklearn.preprocessing import StandardScaler
# 표준화 진행
# StandardScaler().fit_transform()
scale_df = StandardScaler().fit_transform(knn_df)
import pandas as pd
from sklearn.impute import KNNImputer
# KNNImputer 객체 생성
# K(이웃의 수) 지정(3개의 평균으로 계산)
imputer = KNNImputer(n_neighbors=3)
# KNN을 사용하여 결측치 대체
filled_df = pd.DataFrame(imputer.fit_transform(scale_df), columns=knn_df.columns)
* k 값을 지정하여 KNNImputer 객체를 생성할 수 있다.
다음주부터는 머신러닝 학습주차인데 미리 맛보기로 체험해볼 수 있었다.
이상치 식별
Z-Score
Z 값은 X 에서 평균을 뺀 데이터를 표준편차로 나눈 값, 표준점수라고도 한다.
평균에서 ±3 이상이면 이상치로 간주 한다.
IQR
데이터의 25% 지점과 75% 지점 사이의 범위를 사용
이를 벗어나는 값들은 모두 이상치로 간주한다.
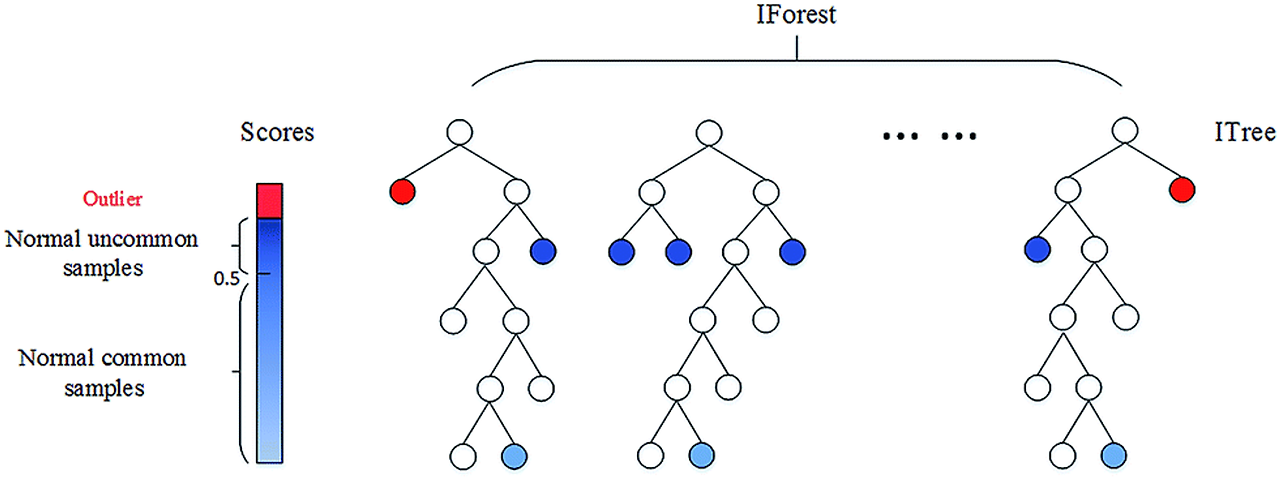
Isolation Forest
:질문에 질문들이 꼬리를 물고 이어져 각 값에 배치되는데,
다른 관측치에 비해 짧은 경로 길이를 가진 데이터를 이상치로 감지
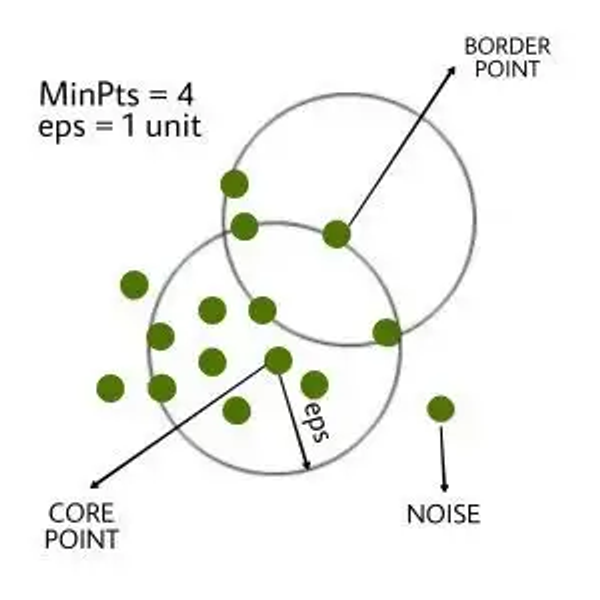
DBScan
: 어떠한 클러스터에도 포함되지 않는 데이터를 이상치로 탐지
이상치를 처리하는 방법은 제거, 대체, 분리 등이 있다.
이상치에 관하여도 분석을 할 수도 있으니 새로운 df 를 생성하여 이상치를 저장해둔다.
- Next
1. 새로운 팀 인사
2. 기초통계 수강
'TIL' 카테고리의 다른 글
| 2024-05-29 (0) | 2024.05.29 |
|---|---|
| 2024-05-28 (0) | 2024.05.28 |
| 2024-05-24 (0) | 2024.05.24 |
| 2024-05-23 (0) | 2024.05.23 |
| 2024-05-22 (0) | 2024.05.22 |